ChuannBlog
高性能基础
基本概念
同步、异步、回调
- 同步、异步指的是提交任务的方式
- 同步指的是提交一个任务,等待任务结束,再提交下一个任务,再等待。。。
- 异步指的是同时提交多个任务,不用等任务结束了才提交下一个任务
- 回调是在异步提交任务的时候才有的概念
- 同步提交任务,任务结束就能获取到结果,对结果进一步处理
- 异步提交任务,不会等到任务结束,那么结果去哪里找?
- 针对这个问题,才有了回调机制的概念,在提交任务的时候指定任务结束后指定处理结果的新任务,便称之为回调
串行、并行、并发
- 串行
- 一个任务启动,运行,结束,第二个任务启动,运行,结束,。。。
- 多个任务挨个执行,不中途执行其他任务的的执行方式称之为串行
- 如一台ATM,人们只能排着队一个个的去取钱
- 并行
- 多个任务同时运行,互不干扰的各自执行称之为并行
- 如多台ATM,人可以去不同ATM取钱
- 多个任务同时运行,互不干扰的各自执行称之为并行
- 并发
- 多个任务看起来像是在并行,称之为伪并行,本质上是串行
- 例子:共有A、B、C三个任务
- A首先开始,运行一会儿,然后保存A此时的状态,
- B开始运行,运行一会儿后,保存B此时的状态,
- C开始运行,运行一会儿,保存C此时的状态,
- 然后切换到A,读取之前A的状态,继续运行A,
- 如此循环
- 从上面的例子可以看出,同一时间只有一个任务在执行,三个任务并没有像并行那样,同时运行
- 需要注意的是,在计算机中,CPU负责执行任务,CPU执行任务的速度远远超过人类的反应速度,因此,在CPU并发执行三个任务的时候,人类就会感觉出三个任务好像同时在执行
- 例子:共有A、B、C三个任务
- 并发实现的核心原理:
- 任务之间的切换
- 保存任务切换前的状态
- 多个任务看起来像是在并行,称之为伪并行,本质上是串行
- 参考阅读:操作系统
效率问题
- 在实际生产中
- 并行的代价是相对较高昂的(需求多核CPU),
- 串行的代价是运行时间相对较长,
- 而并发只是特殊的串行,本质上还是串行,不过并发吸取了并行的一些观念,部分时候会比串行效率高
- 评价执行任务的效率问题,首先要考虑任务的性质:计算密集型、IO密集型
- 通常提升效率的做法就是让CPU闲不下来,利用率100%
- 对于计算密集型任务,只有多核CPU并行才能提升效率,并发并不能提高计算密集型任务的执行效率
- 对于IO密集型任务,当出现IO阻塞,CPU就会空闲等待任务的IO结束,最好的做法就是CPU继续执行下一个任务,因此并发可以很好的解决问题
进程
进程的概念起源于操作系统,是操作系统最核心的概念。
- 操作系统管理进程
- 进程之间的调度由操作系统的负责切换
概念
- 狭义定义
- 进程是正在运行的程序的实例
- 指的是程序的运行过程
- 广义定义
- 计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础
- 含义的变更
- 在早期面向进程设计的计算机结构中,进程是程序的基本执行实体
- 在当代面向线程设计的计算机结构中,进程是线程的容器
- 主要特点
- 进程是一个实体
- 每一个进程都有它自己的地址空间,包括文本区域(text region)、数据区域(data region)、堆栈(stack region)
- 进程是一个执行中的程序
- 程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体
- 进程是一个实体
特征
- 动态性
- 进程的实质是程序在多道程序系统中的一次执行过程,动态产生,动态消亡
- 并发性
- 伪并行,任何进程都可以同其他进程一起并发执行
- 独立性
- 进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位
- 异步性
- 由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进
- 结构特征
- 进程由程序、数据和进程控制块三部分组成
状态
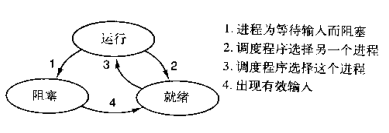
- 运行
- 程序等待I/O,进入阻塞
- 进程运行时间过长,调度程序选择另一个进程,该进程进入就绪
- 就绪
- 调度程序选择进程,进入运行
- 阻塞
- I/O操作出现结果,进入就绪
python使用多进程实现爬虫
from os import getpid
from multiprocessing import Process
import requests
def parse_page(res):
print(getpid(), "正在解析", res.url, len(res.text))
def get_page(_url, callback=parse_page):
print(getpid(), "GET", _url)
response = requests.get(_url)
if response.status_code == 200:
callback(response)
urls = [
"https://www.baidu.com",
"https://www.cnblogs.com",
"https://www.python.org",
"https://www.github.com"
]
if __name__ == '__main__':
for url in urls:
p = Process(target=get_page, args=(url, ))
p.start()
线程
概念
- 轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元
- 由线程ID,当前指令指针(PC),寄存器集合和堆栈组成
- 线程中的实体基本上不拥有系统资源,只是有一点必不可少的、能保证独立运行的资源
- 现在通常认为一个进程有一到多个线程,其中有一个主线程
开线程的两种方式
- 直接实例化threading模块的Thread类,在参数指定线程任务
- 自定义一个线程类,继承Thread类,在run函数定制任务
线程和进程的区别
线程
- 线程的地址空间为进程的地址空间
- 线程可以直接与同进程下线程共享数据
- windows下线程创建开销小
- 同进程下线程可以互相影响
- 更改主线程会影响其他线程运行
进程
- 每个进程有自己独立的地址空间
- 进程必须通过进程间通信共享数据
- 进程创建需要拷贝父进程的信息
- 进程只能控制自己的子进程
- 父进程不影响子进程的运行
python使用多线程实现爬虫
from threading import Thread, get_ident
import requests
def parse_page(res):
print(get_ident(), "正在解析", res.url, len(res.text))
def get_page(_url, callback=parse_page):
print(get_ident(), "GET", _url)
response = requests.get(_url)
if response.status_code == 200:
callback(response)
urls = [
"https://www.baidu.com",
"https://www.cnblogs.com",
"https://www.python.org",
"https://www.github.com"
]
for url in urls:
t = Thread(target=get_page, args=(url,))
t.start()
协程
- 协程是一种用户态的轻量级线程,并不真实存在,是仿造进程和线程在应用程序层面的实现,即协程是由用户程序自己控制调度的
- 可以在一个线程下实现并发效果
协程特点
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 注意:
- 在一个线程下不同任务的切换可由yield,greenlet等实现,但这并不属于协程
- 必须做到能在遇到IO操作才切换到其它协程,才算真的协程
python使用协程实现爬虫
from gevent import monkey;monkey.patch_all()
from gevent.threading import get_ident
import gevent
import requests
def parse_page(res):
print(get_ident(), "正在解析", res.url, len(res.text))
def get_page(_url, callback=parse_page):
print(get_ident(), "GET", _url)
response = requests.get(_url)
if response.status_code == 200:
callback(response)
urls = [
"https://www.baidu.com",
"https://www.cnblogs.com",
"https://www.python.org",
"https://www.github.com"
]
g_list = []
for url in urls:
g = gevent.spawn(get_page, url)
g_list.append(g)
gevent.joinall(g_list)
相关扩展
互斥锁
原理
当一个进程/线程拿到数据使用权后,上一把锁,其余进程/线程看到数据被加锁就进入阻塞状态,直到锁被释放。
- 共享资源
- 多个进程/线程的运行都是独立的,但是有可能出现对同一份资源的使用,这样的资源被称为共享资源
- 数据安全
- 多个进程/线程同时对某一份共享资源,进行处理有可能会出现数据错乱
- 例子中的资源是终端,最终打印出的数据就是乱的
from multiprocessing import Process import os,time def work(): print('%s is running' %os.getpid()) time.sleep(2) print('%s is done' %os.getpid()) if __name__ == '__main__': for i in range(3): p=Process(target=work) p.start() - 特点
- ‘锁’可以保证共享资源的数据安全,在共享资源被锁住的期间,其他进程/线程不可以对共享数据操作
- 同一时间只有一个进程/线程处理数据,牺牲了并发效果,变成了串行,保证了数据安全
-
互斥锁简单实现
from threading import Thread, Lock, get_ident import time lock = Lock() def task(): lock.acquire() print(get_ident(), "开始执行任务") time.sleep(2) print(get_ident(), "结束任务") lock.release() for _ in range(5): t = Thread(target=task) t.start()
全局解释器锁(GIL)(Global Interpreter Lock)
- CPython特性
- CPython的内存管理不是线程安全的。GIL已经存在,其他功能已经发展到依赖于它的实施。
- 每当一个Python脚本开启,首先会创建一个进程,其中必有一个主线程,但脚本想要运行肯定会运行解释器,解释器还带有一些线程,例如内存回收,如果不对数据加锁,就会产生数据正在被回收的时候其他线程,使用了该数据的情况,会导致数据错误
- GIL锁的作用级别是解释器级别,用户无法更改,但是需要了解这种机制
死锁
- 百科定义
- 死锁是指两个或两个以上的进程/线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程/线程称为死锁进程/线程。
- 四个必要条件
- 互斥条件 指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
- 请求和保持条件 指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
- 不剥夺条件 指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
- 环路等待条件 指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
- 互斥锁引起的死锁
- 当加锁资源超过两个且进程/线程超过两个
- 一个进程/线程占有了A资源,进入等待B资源的阻塞状态,另一个进程/线程占有了B资源,进入等待A资源的阻塞状态,两个进程/线程互相处于阻塞对方所占有的资源的状态,且无法释放自己的资源,进入死锁状态
- 死锁解决办法
- 递归锁:RLock类
- 只能解决对同一把锁的死锁
- 增加资源
- 银行家算法
- 递归锁:RLock类
- 死锁实例1
- 该实例中仅有一个线程就会造成死锁
- 可以使用RLock解决
from threading import Thread, Lock, get_ident import time A = Lock() def task(): print(get_ident(), "正在等待A资源") A.acquire() print(get_ident(), "拿到A资源") print(get_ident(), "第二次等待A资源") A.acquire() print(get_ident(), "第二次拿到A资源") time.sleep(1) A.release() print(get_ident(), "A资源使用完毕") A.release() print(get_ident(), "第二次A资源使用完毕") for _ in range(1): t = Thread(target=task) t.start() - 死锁实例2
- 该实例中,如果只有一个线程,则不存在问题
- 但是当存在两个以上线程时就会出现某两个线程互相等待对方持有的资源,产生死锁
from threading import Thread, Lock, get_ident import time A = Lock() B = Lock() def task(): print(get_ident(), "正在等待A资源") A.acquire() print(get_ident(), "拿到A资源") print(get_ident(), "正在等待B资源") B.acquire() print(get_ident(), "拿到B资源") time.sleep(1) A.release() print(get_ident(), "A资源使用完毕") time.sleep(1) print(get_ident(), "第二次等待A资源") A.acquire() print(get_ident(), "第二次拿到A资源") time.sleep(1) A.release() print(get_ident(), "A资源使用完毕") B.release() print(get_ident(), "B资源使用完毕") for _ in range(3): t = Thread(target=task) t.start()
生产者消费者模型
- 共享资源
- 概念 多个进程/线程的运行都是独立的,但是有可能出现对同一份资源的使用,这样的资源被称为共享资源
- 关于数据交互
- IPC(进程间通信)
- 队列Queue
- 管道
- 共享数据
- Manager
- IPC(进程间通信)
- 生产者和消费者不直接交流,通过缓冲区交流,这是异步且并发的
- 缓冲区在Python中通常用消息队列实现
I/O模型
同步/异步/阻塞/非阻塞
- 同步/异步
- 描述提交任务的规则
- 阻塞/非阻塞
- 描述进程/线程的两种状态